BP神经网络识别Jaccount验证码
本文基于本人的课程期末作业,不允许任何形式的转载,如有抄袭等行为后果自负。
课程大作业是写一个单字符识别的简单BP网络,我怎么能甘于做这么个玩意儿(笑),我的目标是Jaccount登陆时的真实验证码!经过不断尝试,识别率已经可以达到99%!远高于常规OCR识别准确率。
项目已开源在Github:https://github.com/MXWXZ/Jaccount-Anti-Captcha
基于GPL-3.0协议
灵感来源
有大佬学长写了个选课插件Electsys++,这个插件是可以自动登陆Jaccount的,免去输密码的麻烦,关键是它还可以自动识别验证码,所以我的目标就是复现这个功能,看了看源码他用JS写了个神经网络来识别,作业要求不允许使用现成的库,加上我又没有TITAN XP之类的玩意儿,所以准备用Python和C++实现。
前期准备
首先我们去看看Jaccount的登陆界面,登陆界面验证码的图片地址类似 https://jaccount.sjtu.edu.cn/jaccount/captcha?1530447994180,后面参数不管他,我们访问 https://jaccount.sjtu.edu.cn/jaccount/captcha 即可获取到一个验证码。
多尝试几次就发现验证码有下面几个规律:
- 验证码图片为100*40
- 验证码为4-5个字符
- 每个字符大致大小均在15*20内
- 字符分布位置不定但均在图片内
- 字符没有扭曲之类的严重干扰,背景无干扰
这为接下来的识别做好了准备。
样本抓取
首先我们需要获取足够多的样本,为此我写了一个python程序来爬,由于需要保证正确,我又比较懒,就用了pytesseract作为OCR辅助识别,会显示OCR识别结果,如果正确则按下空格,该图片保存在src目录下作为训练样本,文件名即为验证码,如果不正确则按其他键,该图片被忽略。
当然样本还是有要求的,由于暂时无法解决粘连字符的问题,所以我样本挑选的都是分开很大的图片,保证样本的完全正确,最终我弄了226个训练样本,平均一个4个字母计大概每个字符有30-40个样本训练,应该是可以了。
样本处理
前面说了神经网络不能用轮子,加上没有卡来搞,所以网络的计算就用C++进行了,又由于C++图片处理相当麻烦,我就先用python处理完之后写入文件,然后只要读取它就行了。使用python中的PIL库处理一下图片,加强特征。具体做法:
- 图像灰度化
- 对比度增强
- 图像增强
- 二值化
这时候图片已经基本上没有干扰了,接着就可以分割字符啦!因为暂时没想到什么好办法,目前程序不考虑粘连字符的处理,分割依据为从左到右第一个出现黑色的列和在此之后第一个没有黑色的列之间为第一个字符,以此类推切割出4张图,然后每张图取从上往下第一行有黑色的列和从下往上第一行有黑色的列之间为字符区域(这样可以防止i之类有间隔的字母),然后把切割下的字符统一移动到一个15*20的纯白背景左上角),分割结束后把分割下的字符图片写入data.txt文件就可以了。
因为我们已经二值化了,每个像素以0/1即可代替黑白,文件格式为字符+图片数据(0/1),每一行有301个字符。
BP网络训练
借鉴网上代码,用C++搞定了网络,下面就是训练了,把数据读出来,输入是一个300维的向量,就是图片的数据,输出是26维向量,除了正确的字母为1,其他均为0。调整几次参数后训练一晚上。误差已经在0.03左右了,目前来讲应该已经够了。然后就是测试一下预测了,把一张图片处理后数据扔进去,然后看输出,基本上都是0-1的值,值最大的就是预测字母了,乘个100就可以搞成可能性了。训练了692轮,997个样本字符识别出了990个,准确率99.3%,相当漂亮啊!然后我们搞点新的图片发现识别率也是相当高的(见图中的预测和答案),虽然像x这些特征少容易混淆的图片“可能性”只有30%,但仍然是所有字符中最高的(我输出最大3个可能性的字符)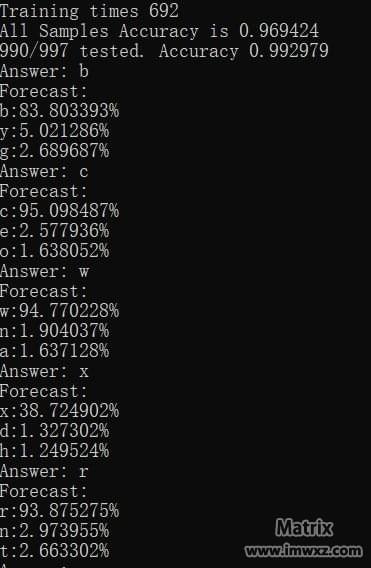
演示
最后就是一个demo演示了,一个python文件抓取一张图,二值化等处理后保存到文件,执行c++程序输出,同时显示出原图作比较,可以看出在没有粘连字符情况下识别率几乎是100%!而有了粘连字符则只会识别第一个或者识别错误,这个等以后有了解决方法再说吧。
 微信
微信 支付宝
支付宝